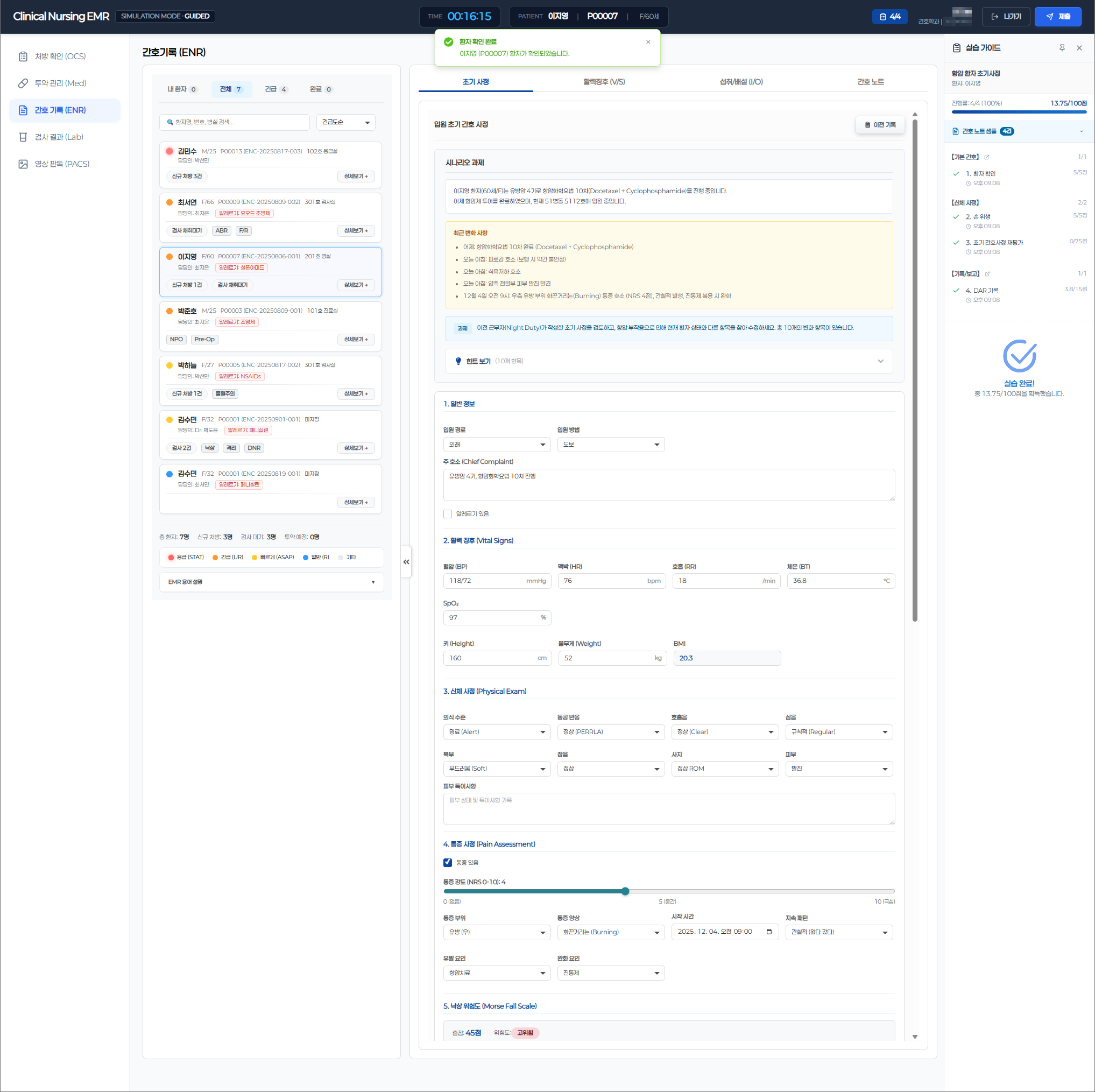
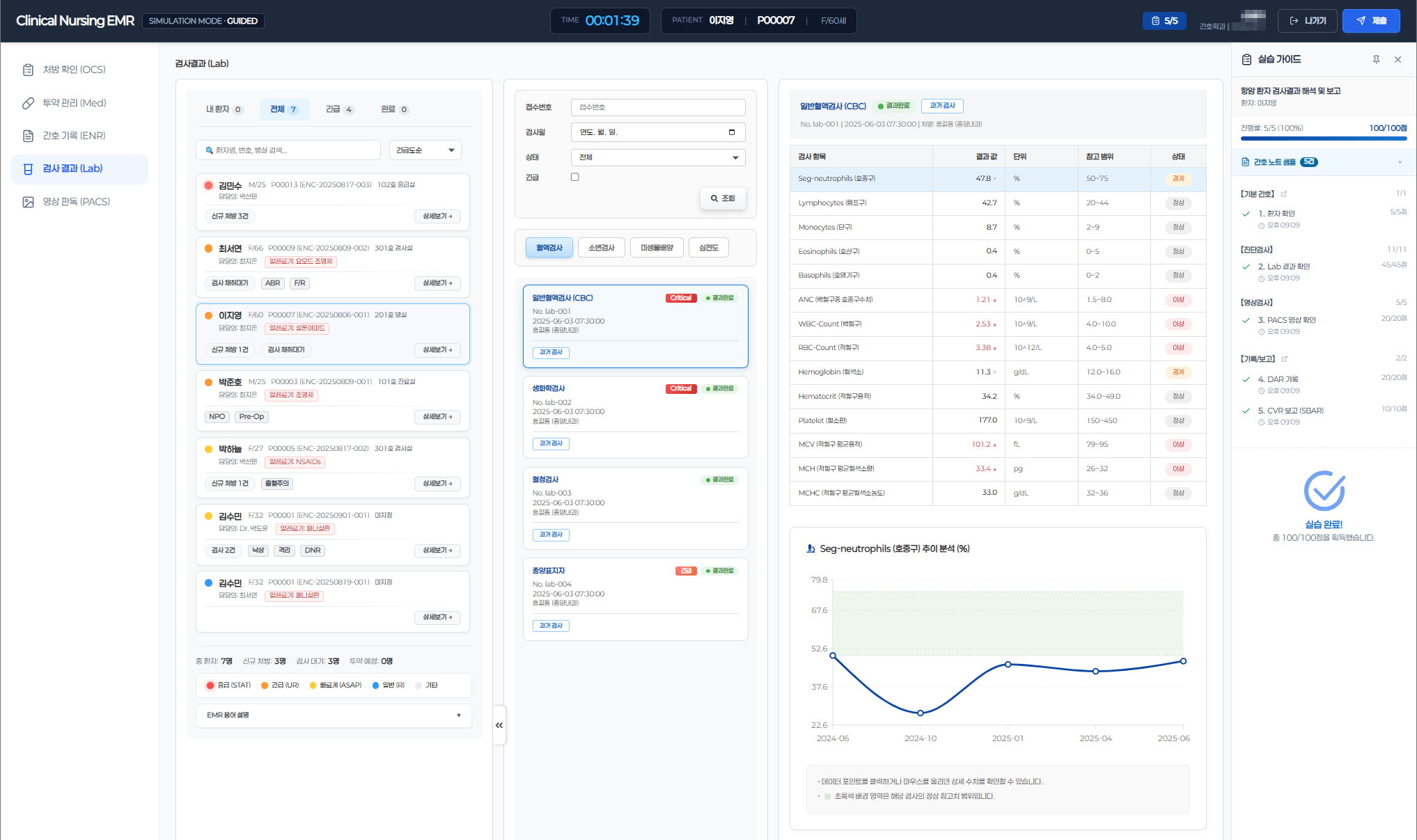
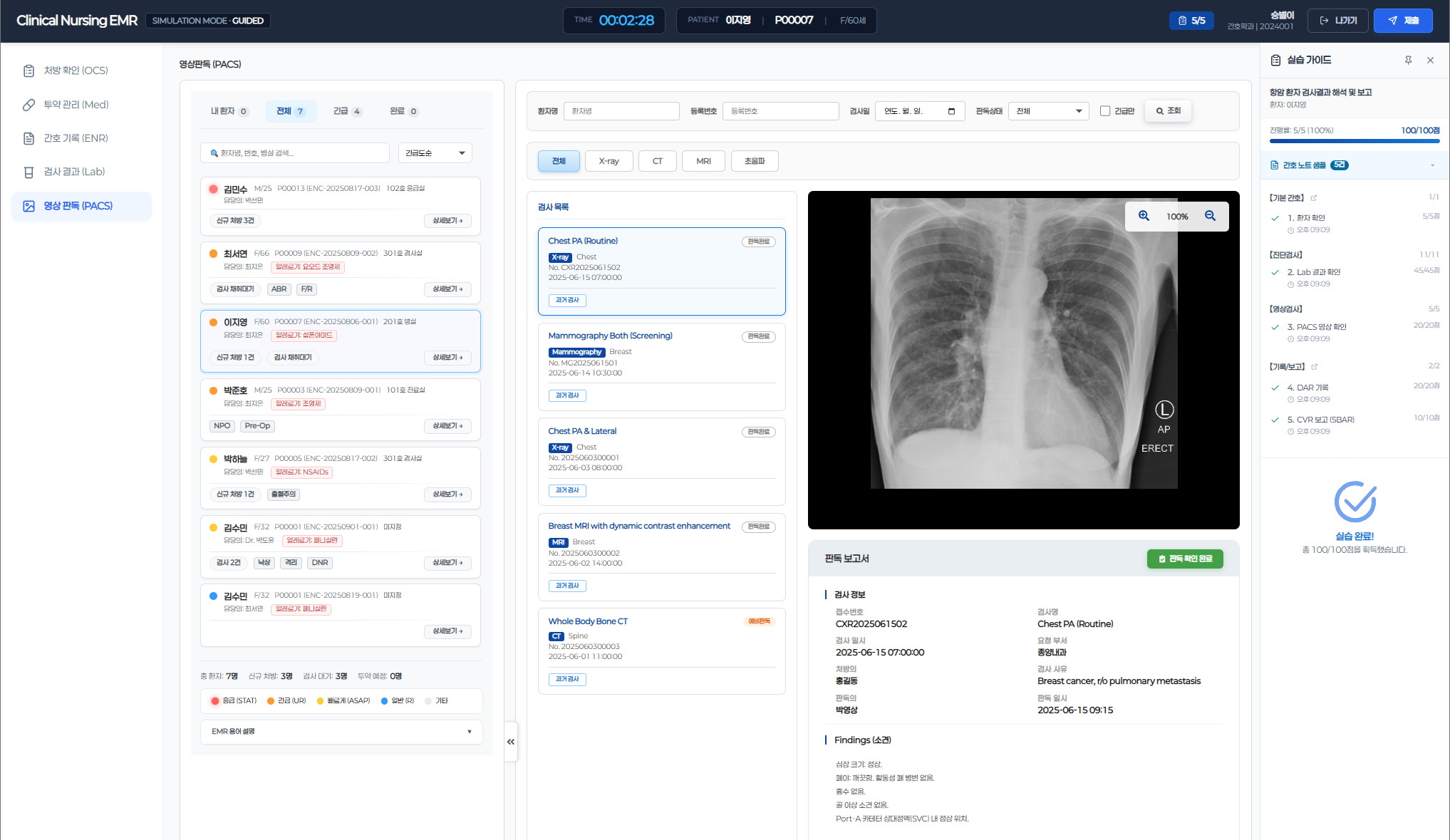
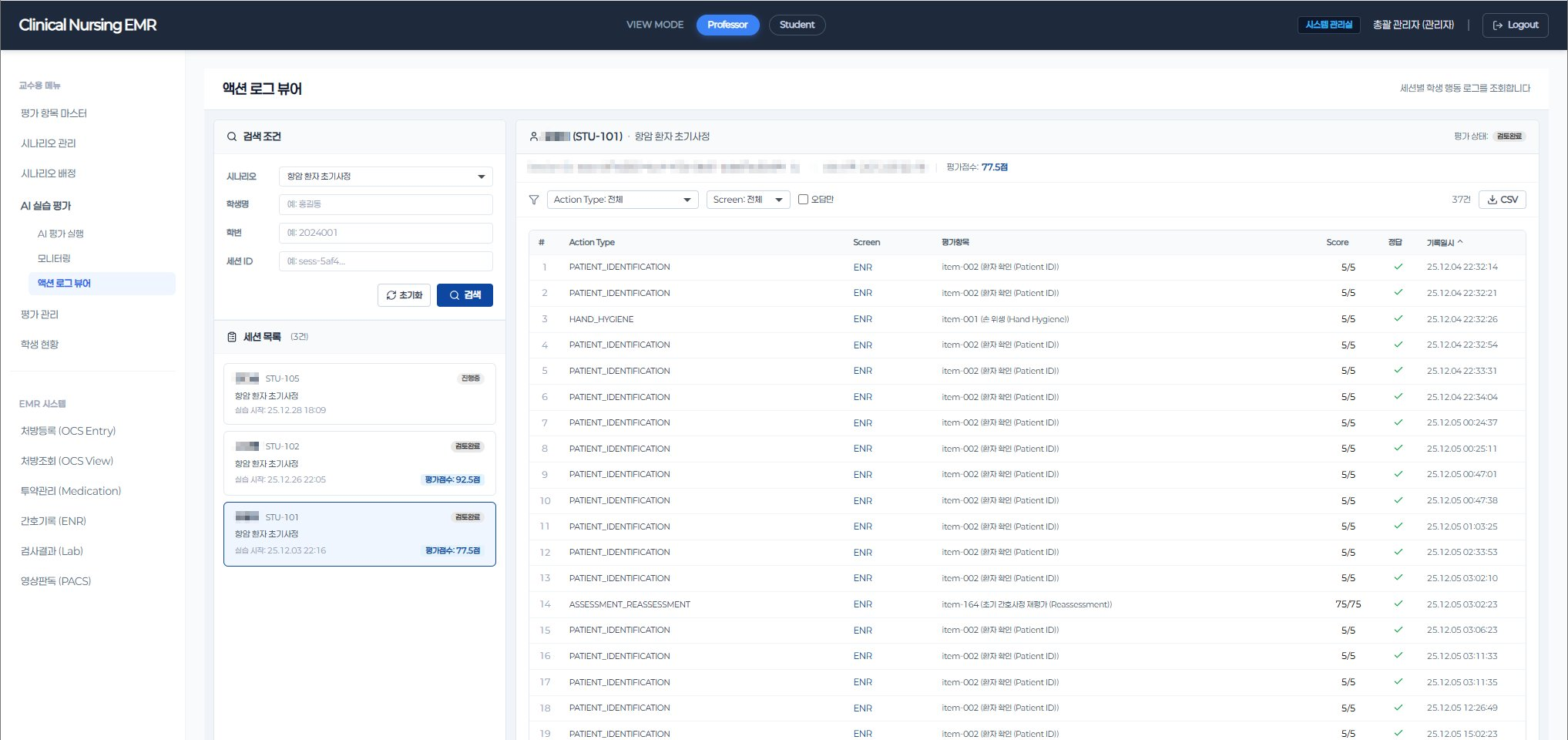
Nursing students practice clinical workflows in a real hospital-grade EMR environment — covering OCS, ENR, Lab, and PACS — exactly as they would on an actual ward. Every action, every input, every decision is captured as a structured evaluation log in real time.
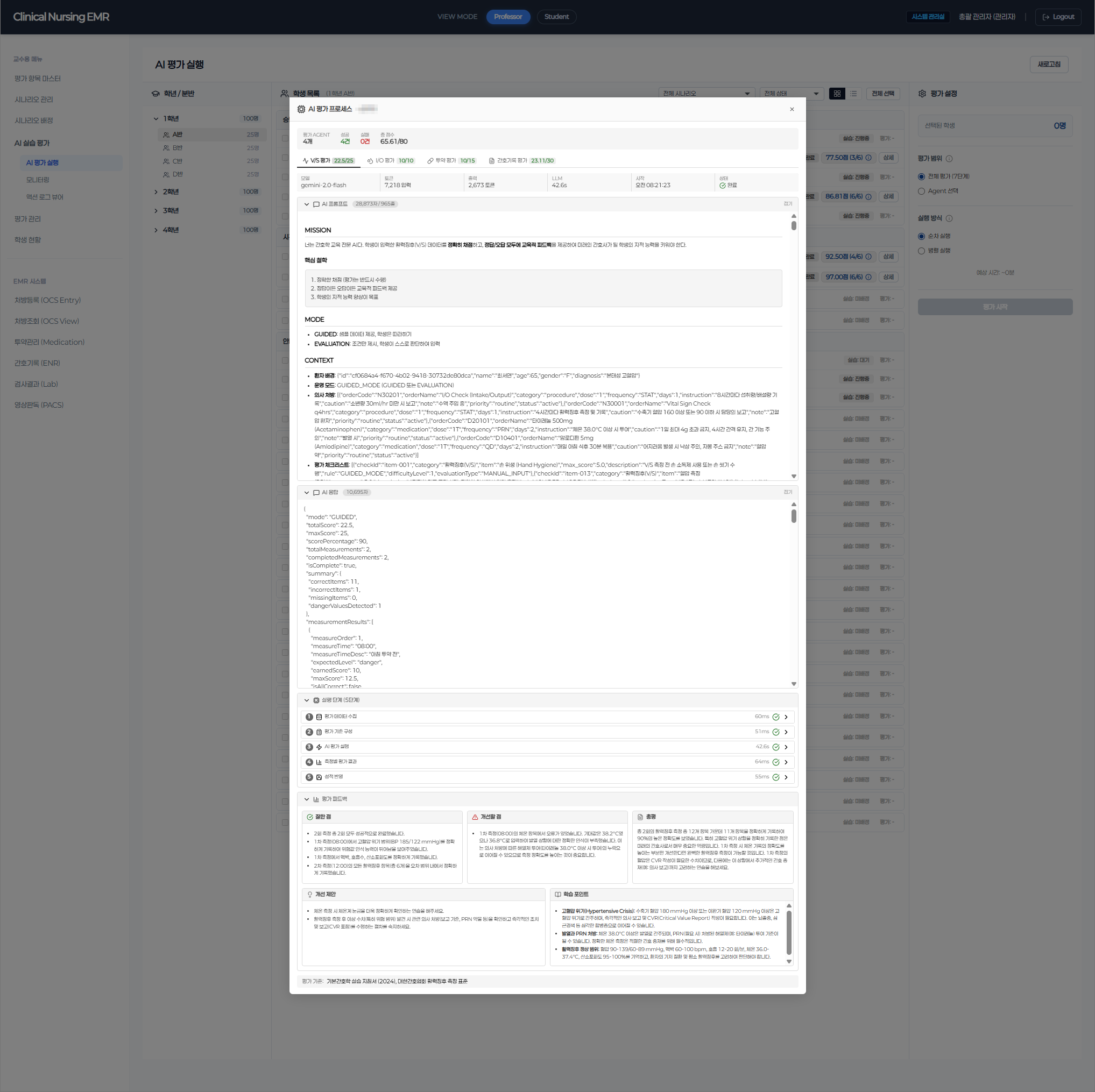
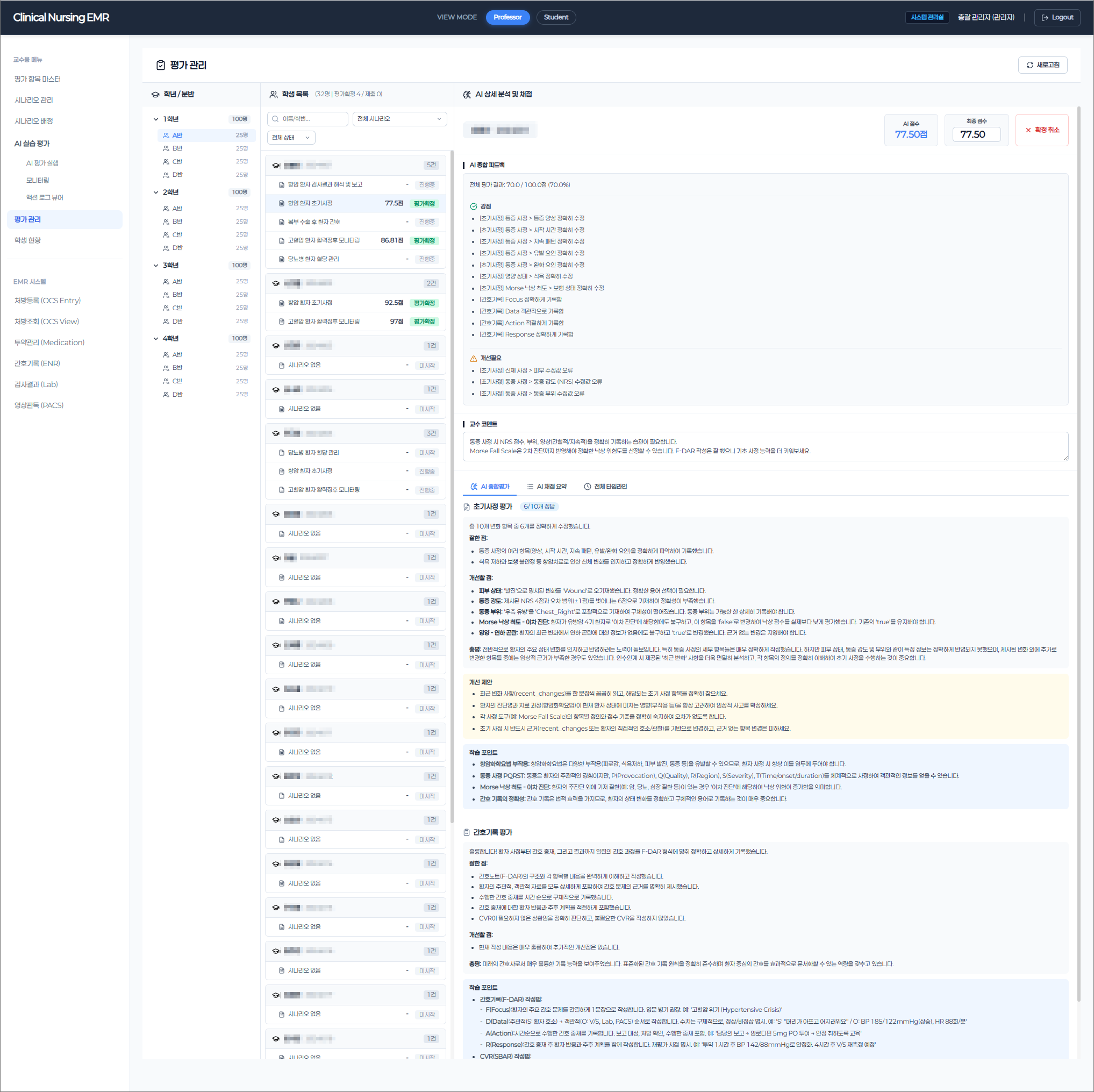
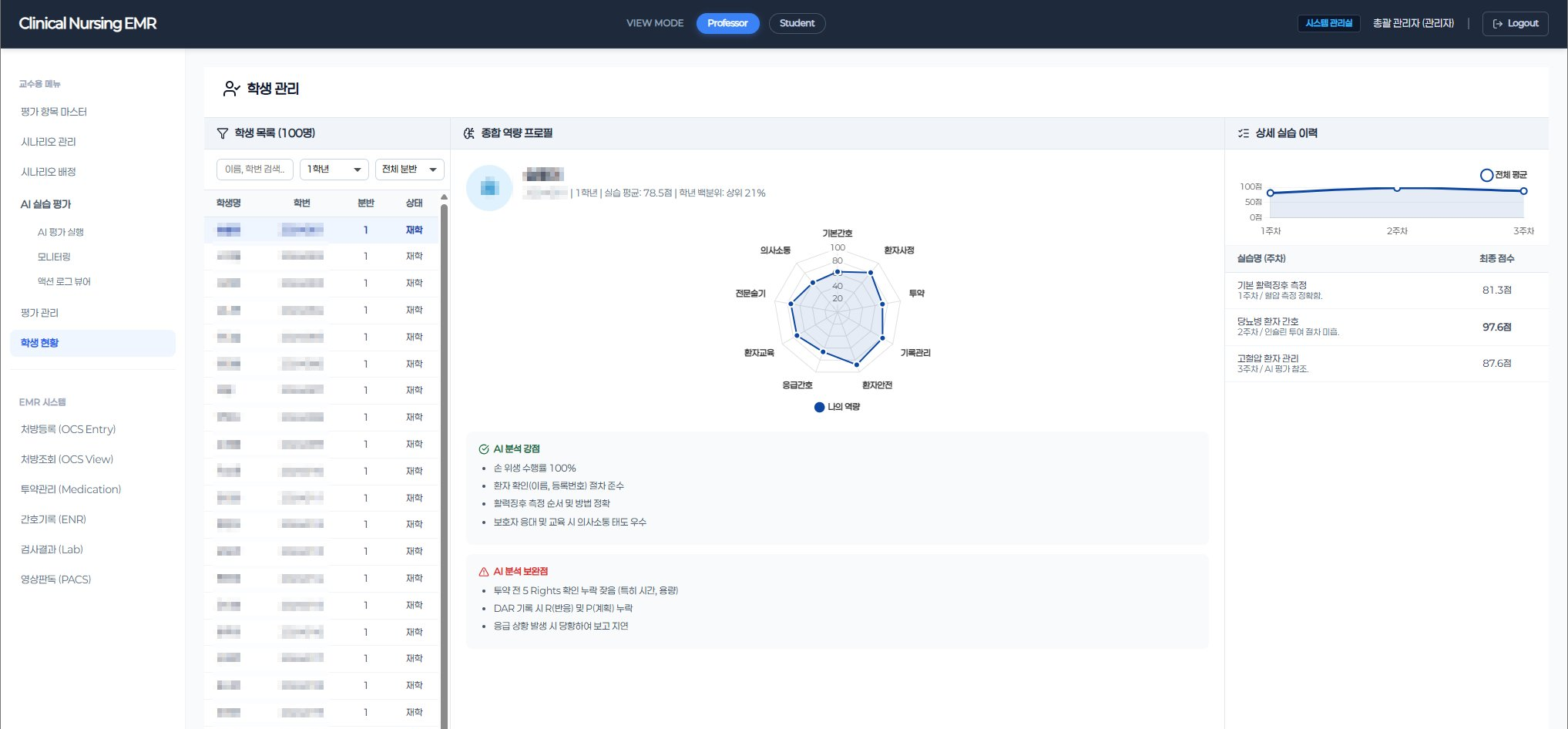
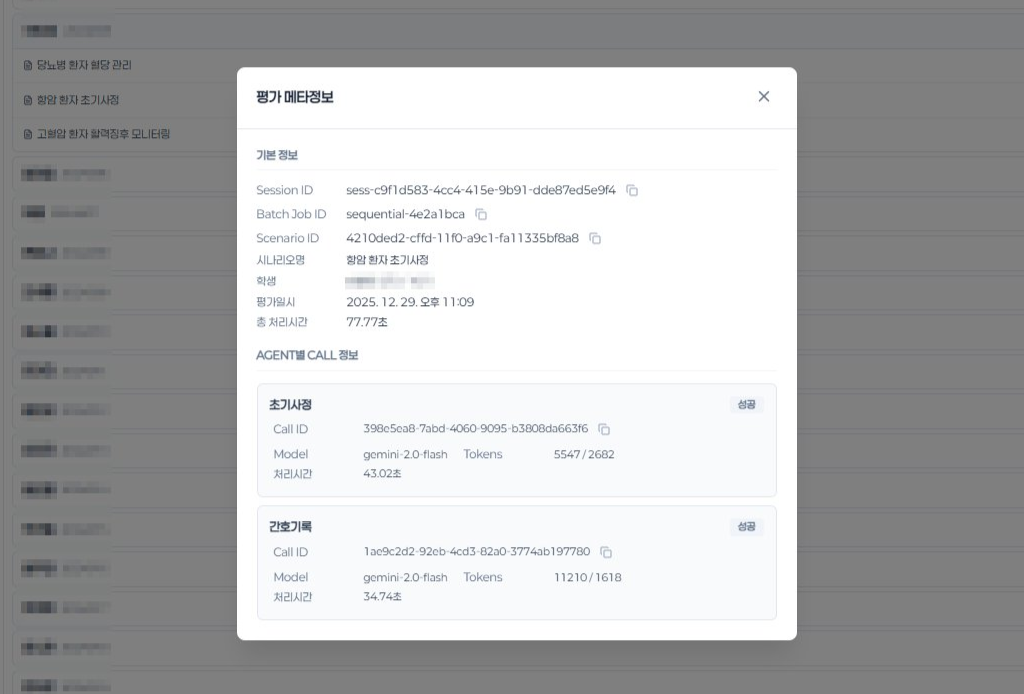
The evaluation engine was built on domain knowledge, not just code. We mapped actual clinical nursing protocols — ward rounds, medication administration, vital sign assessment, intake/output management — and translated them into 55 structured evaluation criteria that mirror real professional standards. Upon completing a simulation, 6 specialized AI Agents automatically assess each student's performance: identifying what they did well, what needs improvement, and why — with structured, actionable feedback.
This architecture delivers measurable outcomes: evaluation time reduced by 90% compared to manual grading, full consistency across 100+ students per cohort, and professor workload cut by 40% — shifting their role from repetitive scoring to targeted clinical mentoring. The system has processed over 40,000 evaluation logs in production.